Introducción
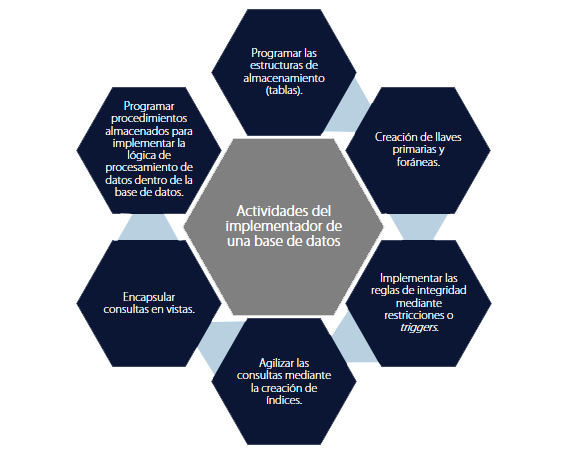
Una vez realizado el diseño de la base de datos y obtenido el modelo relacional, ha llegado el momento de implementarlo (programarlo) en un manejador de base de datos específico. Para realizar esto, será necesario determinar cuál nos conviene. Hoy en día existe una gran variedad de ellos, desde los que cuentan con licencia de uso comercial, hasta los basados en la postura del software libre.
Algunos de los aspectos relevantes para la selección son: el volumen de información que pueden almacenar (generalmente medido en megabytes o terabytes); el número de usuarios que pueden acceder al mismo tiempo; sus ventajas en el manejo de transacciones; su velocidad de respuesta a un número considerable de transacciones; y sus características para imponer seguridad a los datos.
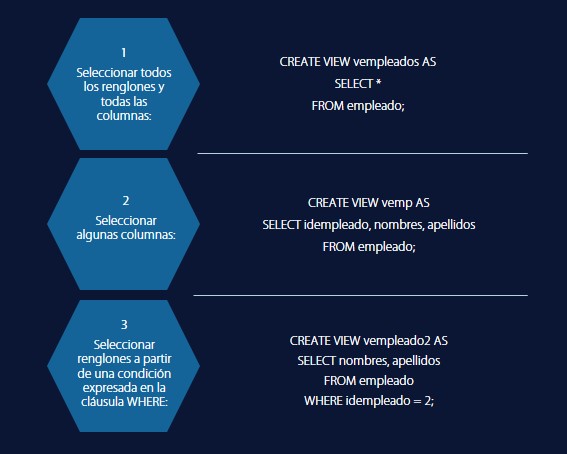
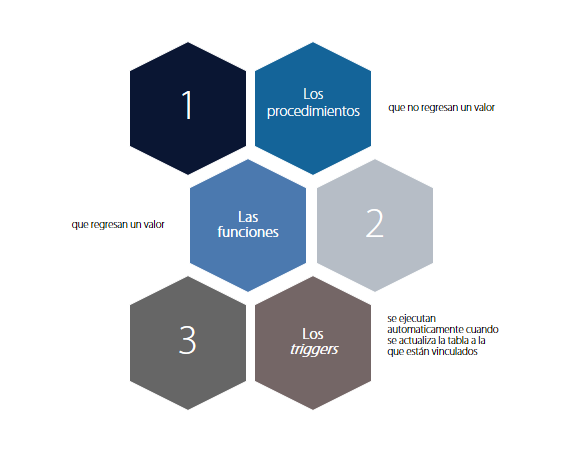
La programación en una base de datos relacional se realiza con el lenguaje SQL; éste es un lenguaje estándar y, si bien hay diferencias de programación entre los distintos manejadores de bases de datos, los comandos más utilizados, generalmente son los mismos.
Posteriormente, podrás realizar tres actividades de aprendizaje y una autoevaluación para verificar tus conocimientos adquiridos; además, si lo crees necesario, puedes revisar nuevamente el contenido y realizar las actividades para obtener un mejor desempeño.
Base de datos, tabla