Una de las aplicaciones fundamentales de la criptografía moderna es la función hash, también conocida como función sólo de ida, función unidireccional o función resumen.
El contenido del tema va dirigido a cualquier persona que busque comprender el funcionamiento básico de las funciones hash y sus aplicaciones.
Una de las aplicaciones fundamentales de la criptografía moderna es la función hash, también conocida como función sólo de ida, función unidireccional o función resumen. Los valores que regresa una función hash son conocidos como valor hash, código hash, hash sum, resumen o simplemente hash.
La función hash se puede definir como una función computacionalmente eficiente que asigna cadenas binarias o mensajes de longitud arbitraria a cadenas binarias de cierta longitud fija o constante, generalmente más pequeñas, llamadas valores hash. Entre sus aplicaciones están la emisión de certificados, las firmas digitales, la generación de llaves y la verificación de contraseñas.
Mensaje = m Función resumen = h(m)
Resultado de la función resumen = ri

Elaboración propia. Esquema de función hash o función resumen [esquema].
Las funciones hash generalmente son públicamente conocidas y no implican el uso de llaves secretas. Cuando se utilizan para detectar si la entrada del mensaje ha sido alterada se denominan códigos de detección de modificación (MDC, Modification Detection Codes). De la misma manera, existen funciones hash que involucran el uso de una llave secreta para proporcionar autenticación de origen de datos, así como integridad de datos. Esta técnica se denomina código de autenticación de mensajes (MAC, Message Authentication Code).
La función hash debe cumplir con ciertas propiedades para ser considerada una función hash criptográfica segura, las cuales son las siguientes:
Si tenemos un hash h(m), debe ser computacionalmente imposible encontrar m a partir de dicho hash. La función h(m) no tiene función inversa (no es una función uno a uno).
A partir de un mensaje de cualquier longitud, el hash h(m) debe tener una longitud fija. Normalmente la longitud de h(m) es menor que el mensaje m.
Dado cualquier mensaje m debe ser computacionalmente fácil calcular h(m).
Dado un hash h(m) debe ser una función compleja de todos los bits del mensaje m: si se modifica un solo bit del mensaje m, h(m) deberá cambiar la mitad de sus bits aproximadamente.
Debe ser computacionalmente imposible si se conoce m, encontrar otro m' tal que h(m) = h(m'). Esto se conoce como resistencia débil a las colisiones.
Debe ser computacionalmente difícil encontrar un par (m, m') de forma que h(m) = h(m'). Esto se conoce como resistencia fuerte a las colisiones.
Hash de mensajes
Una función hash es una función unidireccional que crea una huella digital de longitud fija del mensaje de entrada. La longitud de la entrada de la función no debe afectar su funcionamiento. La salida h(m) siempre tendrá una longitud fija (normalmente de 128 bits, 160 bits o 256 bits).
De esta manera una función hash deberá:

Estructura de una función hash
En general, las funciones hash tienen una estructura similar a la de las funciones de compresión, que dan como resultado bloques de longitud n a partir de bloques de longitud m. Estas funciones se encadenan de forma iterativa, haciendo que la entrada en el paso i sea función del i-ésimo bloque del mensaje y de la salida del paso i - 1. En general, se suele incluir en alguno de los bloques del mensaje m (al principio o al final) información sobre la longitud total del mensaje. De esta forma se reducen las probabilidades de que dos mensajes con diferentes longitudes den el mismo valor en su resumen.
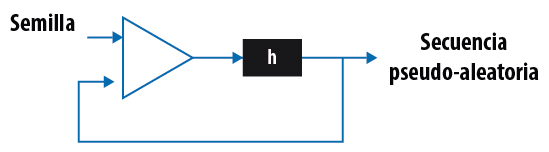
Elaboración propia. (2020). Estructura de función hash [esquema].
Ahora, veamos un ejemplo del uso de una función hash en un protocolo llamado protocolo de desafío-respuesta (en inglés challenge-response protocol). Estos protocolos tienen como objetivo la autenticación de entidades mediante el uso de un desafío o problema. Si la entidad conoce la solución a este problema, entonces podemos confiar en ella.
Imaginemos el siguiente escenario.
a. Funcionamiento de MD5 y sus ataques
MD5 es uno de los más populares algoritmos de generación de hash, debido en gran parte a su inclusión en las primeras versiones de PGP, resultado de una serie de mejoras sobre el algoritmo MD4, diseñado por Ron Rivest. MD5 procesa los mensajes de entrada en bloques de 512 bits y produce una salida de 128 bits.
Al ser m un mensaje de b bits de longitud, en primer lugar, se alarga m hasta que su longitud sea exactamente 64 bits inferior a un múltiplo de 512. El alargamiento se lleva a cabo añadiendo un uno, seguido de tantos ceros como sea necesario. En segundo lugar, se añaden 64 bits con el valor de b, empezando por el byte menos significativo. De esta forma tenemos el mensaje como un número entero de bloques de 512 bits y además le hemos añadido información sobre su longitud.
Seguidamente, se inicializan cuatro registros de 32 bits con los siguientes valores hexadecimales:
A = 67452301
B = EFCDAB89
C = 98BADCFE
D = 10325476
Se continua con el lazo principal del algoritmo, que se repetirá para cada bloque de 512 bits del mensaje. En primer lugar, copiaremos los valores de A, B, C y D en otras cuatro variables, a, b, c y d. Luego definiremos las siguientes cuatro funciones:
F(X, Y, Z) = (X ∧ Y) ∨ ((¬X) ∧ Z)
G(X, Y, Z) = (X ∧ Z) ∨ (Y ∧ (¬Z))
H(X, Y, Z) = X ⊕ Y ⊕ Z
I(X, Y, Z) = Y ⊕ (X ∨ (¬Z))
Ahora representaremos por mj el j-ésimo bloque de 32 bits del mensaje m (de 0 a 15) y definiremos otras cuatro funciones:
FF(a, b, c, d, mj ,s, ti) representa a = b + ((a + F(b, c, d) + mj + ti) ⊲ s)
GG(a, b, c, d, mj ,s, ti) representa a = b + ((a + G(b, c, d) + mj + ti) ⊲ s)
HH(a, b, c, d, mj ,s, ti) representa a = b + ((a + H(b, c, d) + mj + ti) ⊲ s)
II(a, b, c, d, mj ,s, ti) representa a = b + ((a + I(b, c, d) + mj + ti) ⊲ s)
En donde la función a ⊲ s representa desplazar circularmente el valor a s bits a la izquierda.
Las 64 operaciones que se realizan en total quedan agrupadas en cuatro rondas.
Finalmente, los valores resultantes de a, b, c y d son sumados con A, B, C y D. Se procesa el siguiente bloque de datos. El resultado final del algoritmo es la concatenación de A, B, C y D.
A modo de curiosidad, diremos que las constantes ti empleadas en cada paso son la parte entera del resultado de la operación 232 · abs(sin(i)), estando i representado en radianes.
En los últimos tiempos el algoritmo MD5 ha mostrado ciertas debilidades, aunque sin implicaciones prácticas reales, por lo que se sigue considerando en la actualidad un algoritmo seguro, aunque su uso tiende a disminuir.
b. Funcionamiento SHA-1 y sus ataques
El algoritmo SHA-1 fue desarrollado por la NSA, para ser incluido en el estándar DSS (Digital Signature Standard). Al contrario de los algoritmos de cifrado propuestos por esta organización, SHA-1 se considera seguro y libre de puertas traseras, ya que favorece a los propios intereses de la NSA que el algoritmo sea totalmente seguro. Produce firmas de 160 bits a partir de bloques de 512 bits del mensaje original.
El algoritmo es similar a MD5 y se inicializa igual que éste, añadiendo al final del mensaje un uno seguido de tantos ceros como sea necesario hasta completar 448 bits en el último bloque, para luego yuxtaponer la longitud en bytes del propio mensaje. A diferencia de MD5, SHA-1 emplea cinco registros de 32 bits en lugar de cuatro:
A = 67452301
B = EFCDAB89
C = 98BADCFE
D = 10325476
E = C3D2E1F0
Una vez que los cinco valores están inicializados, se copian en cinco variables, a, b, c, d y e. El lazo principal tiene cuatro rondas con 20 operaciones cada una:
F(X, Y, Z) = (X ∧ Y) ∨ ((¬X) ∧ Z)
G(X, Y, Z) = X ⊕ Y ⊕ Z
H(X, Y, Z) = (X ∧ Y) ∨ (X ∧ Z) ∨ (Y ∧ Z)
La operación F se emplea en la primera ronda (t comprendido entre 0 y 19), la G en la segunda (t entre 20 y 39) y en la cuarta (t entre 60 y 79), y la H en la tercera (t entre 40 y 59); además, se emplean cuatro constantes, una para cada ronda:
K0 = 5A827999
K1 = 6ED9EBA1
K2 = 8F1BBCDC
K3 = CA62C1D6
El bloque de mensaje m se divide en 16 partes de 32 bits m0 a m15 y se convierte en 80 trozos de 32 bits w0 a w79 usando el siguiente algoritmo:
wt = mt para t = 0 … 15
wt = (wt−3 ⊕ wt−8 ⊕ wt−14 ⊕ wt−16) ⊲ 1 para t = 16 … 79
Como curiosidad diremos que la NSA introdujo el desplazamiento a la izquierda para corregir una posible debilidad del algoritmo, lo cual supuso modificar su nombre y cambiar el antiguo (SHA) por SHA-1.
El pseudocódigo de la función SHA-1 queda de la siguiente manera:
PARA t := 0 HASTA 79
i := t div 20
tmp := (a ⊲ 5) + A(b, c, d) + e + wt + Ki
e := d
d := c
c := b ⊲ 30
b := a
a := tmp
Donde:
• A la función F
• G o H según el valor de t
• F para t ∈ [0, 19]
• G para t ∈ [20, 39] y [60, 79]
• H para t ∈ [40, 59])
Después, los valores desde a hasta e son sumados a los registros A hasta E y el algoritmo continúa con el siguiente bloque de datos.
c. Funcionamiento SHA-2 y SHA-3

SHA-2 incluye un significativo número de cambios respecto a su predecesor SHA-1. Los cambios consisten en un conjunto de cuatro funciones hash de 224, 256, 384 o 512 bits.
En 2005 se identificaron fallas de seguridad en SHA-1, permitiendo que existiera una debilidad matemática y evidenciando así la necesidad de elaborar una función hash más fuerte. Aunque SHA-2 se comporta de forma parecida al algoritmo SHA-1, estos ataques no han sido extendidos satisfactoriamente a SHA-2.
Las funciones hash SHA-2 están implementadas en una gran variedad de aplicaciones y protocolos de seguridad; por ejemplo, TLS y SSL, PGP, SSH, S/MIME, Bitcoin, PPCoin y IPsec.
La moneda criptográfica Bitcoin depende en gran medida en un doble uso del SHA-256. El SHA-256 es usado para identificar los paquetes de software de Debian GNU/Linux.
SHA-1 y SHA-2 son algoritmos hash de seguridad requeridos por ley en ciertas aplicaciones del Gobierno de Estados Unidos, junto con el uso de otros algoritmos y protocolos criptográficos, para la protección de información clasificada y sensible.

Velasco, R. (2015). SHA-3: El nuevo estándar de hash aprobado por el NIST [fotografía]. Tomada de https://www.redeszone.net/2015/08/07/sha-3-nuevo-estandar-hash-aprobado-nist/
SHA-3 es el último miembro de la familia de estándares Secure Hash Algorithm, publicado por NIST el 5 de agosto de 2015. El código fuente de la implementación de referencia se dedicó al dominio público. Aunque es parte de la misma serie de estándares, SHA-3 es internamente diferente de la estructura de los algoritmos MD5, SHA-1 y SHA-2.
SHA-3 es un subconjunto de la familia primitiva criptográfica más amplia llamada Keccak. Los autores del Keccak han propuesto usos adicionales para la función, (todavía) no estandarizada por el NIST, en donde se incluye el uso de un cifrado de flujo, un cifrado de autenticado para el sistema y el uso de un "árbol" hash, el cual es un esquema de hash más rápido para ciertas arquitecturas de computadoras.
Keccak se basa en un enfoque novedoso llamado construcción de esponjas. La construcción de esponja se basa en una amplia función aleatoria o permutación aleatoria y permite ingresar ("absorber" en la terminología de esponja) cualquier cantidad de datos, y generar (exprimir) cualquier cantidad de datos, mientras actúa como una función pseudoaleatoria con respecto a todas las entradas anteriores. Esto conduce a una gran flexibilidad. El propósito de SHA-3 es que puede ser sustituido directamente por SHA-2 en aplicaciones actuales si es necesario.
Comparación de MD5 y SHA-1
Entre las aplicaciones de los algoritmos hash encontramos:

| Usando hash para obtener una llave privada |
|---|
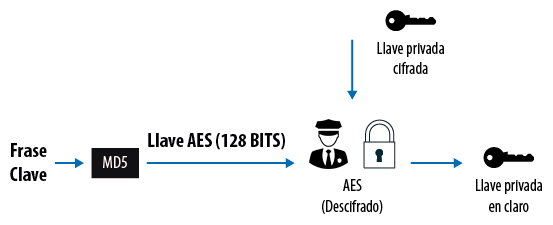 Elaboración propia. (2020). Diagrama de función hash para llaves privadas [esquema]. Las llaves privadas usadas en los esquemas de cifrado simétrico siempre deben estar cifradas. La manera estándar de realizar este proceso es usando una frase clave que será enviada a un algoritmo hash. La salida será siempre la misma y de tamaño fijo, por lo que puede usarse como una llave de cifrado simétrico. Así, el dato a cifrar es una llave privada y la llave para cifrado es el hash de una frase clave y la salida es el cifrado de una llave privada. En la imagen mostramos el proceso de descifrado de dicha llave, que será ejecutado cada que la llave privada sea usada. De esta manera, la llave privada siempre será almacenada de forma segura. |
| Función hash en firma digital |
|---|
Mensaje = m Función Resumen = h(m) Uno de los problemas que busca solucionar la criptografía es ¿cómo podemos verificar la identidad del emisor de un mensaje en un canal inseguro como es Internet? Las funciones hash, en apoyo del esquema de llave pública y privada, permiten solucionar este problema. Creando un resumen del mensaje y luego cifrando ese resumen utilizando la llave privada del emisor se puede enviar la firma S, la cual será descifrada DSpub(S), usando la llave pública del emisor. Luego se calcula el hash del mensaje h(m’), que fue enviado junto con la firma m’ (se puede descifrar si es necesario). Si los dos valores hash son los mismos h(m’) = h(m), la firma digital es autenticada y el mensaje se encuentra íntegro. DSpub(S) = h(m) |
Longitud adecuada para una firma digital
Para decidir cuál debe ser la longitud apropiada de una firma digital, podemos usar la idea de la paradoja del cumpleaños. Parafraseando, podemos crear un ejemplo con base en ella: ¿Cuál es la cantidad de personas que hay que poner en una habitación para que la probabilidad de que el cumpleaños de una de ellas sea el mismo día que el mío y supere el 50 %? Debemos calcular n tal que…
n(1/365) > 0.5
Luego n > 182; sin embargo, ¿cuál sería la cantidad de gente necesaria para la probabilidad de que dos personas tengan el mismo cumpleaños y supere el 50 %? Cada pareja tiene una probabilidad 1/365 de compartir el cumpleaños y en un grupo de n personas hay n(n − 1)/2 parejas diferentes de personas, luego…
n(n − 1)/2 · 1/365 > 0.5
Esto se cumple si n > 19, una cantidad sorprendentemente mucho menor que 182. La consecuencia de esta paradoja es que, aunque resulte muy difícil, dado m calcular un m′ tal que r(m) = r(m′), es mucho menos costoso buscar dos valores aleatorios m y m′, tales que r(m) = r(m′).
En el caso de una firma de 64 bits, necesitaríamos 264 mensajes dado un m para obtener el m′, pero bastaría con generar aproximadamente 232 mensajes aleatorios para que aparecieran dos con la misma firma digital (en general, si la primera cantidad es muy grande, la segunda cantidad es aproximadamente su raíz cuadrada). El primer ataque nos llevaría 600.000 años con una computadora que generara un millón de mensajes por segundo, mientras que el segundo necesitaría apenas una hora.
Hemos de añadir a nuestra lista de condiciones sobre las funciones resumen la siguiente:
• Debe ser difícil encontrar dos mensajes aleatorios m y m′, tales que r(m) = r(m′).
Hoy por hoy se recomienda emplear firmas digitales de al menos 128 bits, siendo 160 bits el valor más usado.
Otro tipo de función resumen son las funciones de autentificación de mensajes, también conocidas como MAC (Message Authentication Codes).
Los MAC se caracterizan fundamentalmente por el empleo de una clave secreta para poder calcular la integridad del mensaje. Puesto que dicha clave sólo es conocida por el emisor y el receptor, el efecto conseguido es que el receptor puede, mediante el cálculo de dicha función, comprobar tanto la integridad como la procedencia del mensaje.
Existe multitud de MAC diferentes, pero lo más común es cifrar el mensaje mediante un algoritmo simétrico en modo CBC y emplear la salida correspondiente al cifrado del último bloque.
Código de autentificación de mensajes en clave-hash (HMAC)
Esta técnica usa un algoritmo hash y una clave simétrica para hacer el valor hash depender de dicha llave. La forma más común de HMAC es hash (llave, hash (llave, mensaje)).
La llave afecta el inicio y el final del proceso de hash.
Nombres de HMAC-hash
• MD5 HMAC-MD5
• SHA-1 HMAC-SHA (recomendado)
HMAC es usado en IPSec y SSL.
Colisión en hash
La colisión en un algoritmo hash es de los ataques más comunes y de las razones por las que un algoritmo deja de ser seguro. Es una situación que se produce cuando dos entradas distintas de una función hash producen una misma salida.
Es matemáticamente imposible que una función hash no presente colisiones, ya que la entrada a una función hash es infinita, mientras que las salidas que puede entregar están en un conjunto finito; sin embargo, las colisiones se producen más frecuentemente en los malos algoritmos. En una función en la cual se pueden introducir datos de longitud arbitraria y que devuelven un hash de tamaño fijo (como MD5), siempre habrá colisiones, debido a que un hash dado puede pertenecer a un infinito número de entradas.
Resistencia fuerte y débil a colisiones
Para un x dado, si resulta computacionalmente fácil encontrar un y ≠ x tal que H(x) = H(y), se habla de una resistencia débil a colisiones. Si resulta computacionalmente difícil encontrar un par (x, y) tal que H(x) = H(y), se habla de una resistencia fuerte a colisiones.
Clasificación
Existe una función de enumeración que asigna a cada valor del dominio una única posición de memoria. No posee colisiones.
La función de hash puede asignar a dos valores distintos el mismo valor hash. x1 ≠ x2 y h(x1) = h(x2) Estos dos valores reciben el nombre de sinónimos. Las estructuras de hashing puros poseen colisiones y en consecuencia se deberán establecer mecanismos para tratarlas. Las estructuras de hash puras se pueden clasificar de la siguiente forma:
• Cerradas: No utilizan un nuevo espacio en memoria.
• Abiertas: Utilizan espacio adicional.
La estructura principal no crece.
La estructura principal se expande a medida que aumenta la cantidad de elementos.
Al final del 2004, científicos chinos de la Universidad de Shandong presentaron un artículo en donde se analizaban las debilidades de las funciones hash, tales como MD5 y SHA-1 en la presencia de colisiones (Wang & Yu, 2005).

Las funciones resumen o funciones hash tienen diversas aplicaciones en criptografía; una de las más importantes es verificar la integridad de datos enviados entre dos entidades.
Ana y Beto están trabajando de forma remota en un documento para la escuela. Después de cada cambio que realizan se mandan el documento por correo electrónico; quieren estar seguros de que cada vez que mandan el documento éste no ha sido modificado por alguien más.

A continuación, podrás evaluar tú mismo el conocimiento adquirido acerca de las funciones hash.
Fuentes de información
Básicas
Bibliografía
Lucena, M. J. (2001). Criptografía y seguridad en computadores (pp. 157-164). Universidad de Jaén.
Menezes, A. J., Van Oorschot, P. C. & Vanstone, S. A. (1997). Handbook of Applied Cryptography (pp. 321-385). CRC Press.
Documentos electrónicos
brainhub. (2020, september 2). C implementation of SHA-3 and Keccak with Init/Update/Finalize API. Github. https://github.com/brainhub/SHA3IUF
Wang, X. & Yu, H. (2005). How to break MD5 and other hash function. https://www.researchgate.net/publication/225230142_How_to_Break_MD5_and_Other_Hash_Functions
Material audiovisual
Computerphile. (8 de noviembre de 2013). Hashing Algorithms and Security - Computerphile [video]. YouTube. https://www.youtube.com/watch?v= b4b8ktEV4Bg
Computerphile. (11 de abril de 2017). SHA: Secure Hashing Algorithm - Computerphile [video]. YouTube. https://www.youtube.com/watch?v=DMtFhACPnTY
Complementarias
Documentos electrónicos
Wikipedia. (2019). MD5. https://es.wikipedia.org/w/index.php?title=MD5&oldid=121189223
Wikipedia. (2020). Paradoja del cumpleaños. https://es.wikipedia.org/w/index.php?title=Paradoja_del_cumplea%C3%B1os&oldid=127562247
Wikipedia. (2020). Pretty Good Privacy. https://es.wikipedia.org/w/index.php?title=Pretty_Good_Privacy&oldid=128744096
Material audiovisual
Hines, G. (9 de marzo de 2011). SHA-1 Hash Tutorial [video]. YouTube. https://www.youtube.com/watch?v= aLvwpJcOy6s
Cómo citar
Aldeco, R. (2021). Funciones hash. Unidades de Apoyo para el Aprendizaje. CUAIEED/Facultad de Ingeniería-UNAM. (Vínculo)