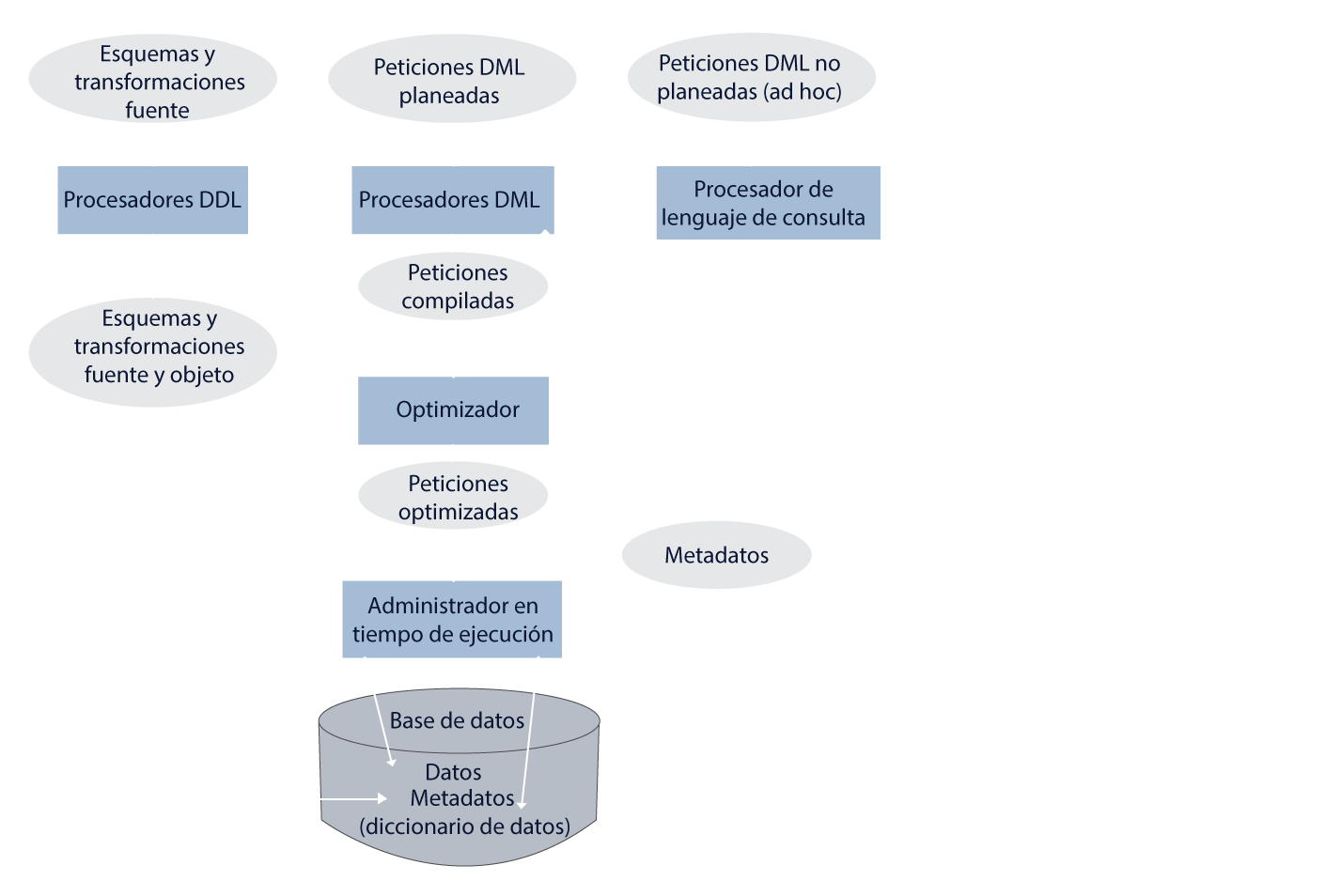
Clasificación
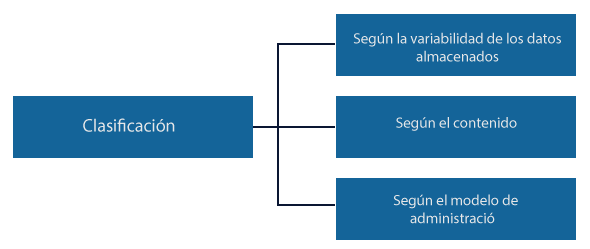
La clasificación de las bases de datos puede hacerse de diferentes maneras, de acuerdo al contexto en que se manejen, utilidad o necesidad que satisfagan.
Tipos de bases de datos
1. Según la variabilidad de los datos almacenados
Bases de datos estáticas
Son bases de datos de sólo lectura que se utilizan, primeramente, para el almacenamiento de datos históricos, y después pueden ser empleadas para analizar la conducta de un conjunto de datos al paso del tiempo, llevar a cabo proyecciones y, sobre todo, para la toma de decisiones.
Bases de datos dinámicas
Contienen información que se modifica con el tiempo y sobre la cual pueden efectuarse operaciones de actualización, eliminación y adicción de datos, así como operaciones básicas de consulta. Ejemplos de este tipo de base de datos son las utilizadas en los supermercados, tiendas de autoservicio y videoclubes y farmacias.
2. Según el contenido
•Base de datos bibliográficos
Contiene índices de las fuentes primarias que permiten su localización. El registro representativo de estas bases posee información relacionada con el autor, fecha de publicación, editorial, título y edición de una publicación determinada. En ocasiones, puede incluirse un extracto o resumen de la publicación original.
Generalmente comprende números, cifras o cantidades. Puede referirse, por ejemplo, a los resultados de análisis de laboratorio o investigación.
•Base de datos de texto completo
Permite almacenar datos de fuentes primarias; por ejemplo, contenidos completos de colecciones de revistas científicas.
•Directorios
Por ejemplo, agendas telefónicas en formato electrónico.
Bases de datos o bibliotecas de información química o biología
Son bases especializadas con información referente a la química, ciencias naturales y médicas. Se clasifican en varios subtipos:
•Bases especializadas que resguardan las secuencias de nucleótidos y proteínas.
•Bases de datos rutas metabólicas.
•Base de datos de estructura: almacena información sobre los modelos experimentales de estructura biomolecular en 3D.
•Base de datos clínica: guarda el registro de los historiales clínicos y tiramientos medicinales.
•Base de datos bibliográfica: almacena registro sobre todo tipo de publicaciones especializada en el campo de la biología, química, medicina y otras áreas; por ejemplo, PubChem, MEdline y EBSCOhost.
3. Según el modelo de administración
Cuando se hace referencia a un modelo de datos se alude básicamente a una descripción de la forma conceptual de cómo van a estar contenidos los datos en una base de datos, y se describen las formas o métodos que serán empleados para almacenar y recuperar la información contenida.
Los modelos de datos son una representación conceptual que a la postre servirá para la implementación de una base de datos eficiente. Esta conceptualización, por lo regular, hace referencia a una serie de algoritmos y conceptos matemáticos que permiten realizar una abstracción de lo que se desea modelar.
Algunos modelos de base de datos empleados en la actualidad:
•Bases de datos jerárquicas
Se basan en una estructura jerárquica para el almacenamiento de los datos. Los datos son organizados en una estructura de árbol compuesta por una serie de nodos de información, donde cada nodo padre puede tener varios nodos asociados hijos. El nodo principal se denomina raíz y todos los nodos terminales o que no tienen nodos asociados son las hojas.
Las bases de datos que trabajan con el esquema jerárquico sólo empleadas comúnmente en el manejo de grandes volúmenes de información, facilitan compartir los datos, ya que su estructura arbórea, por lo general, es muy estable y permite excelente rendimiento, aunque su inconveniente principal es la representación de la redundancia de datos.
•Base de datos de red
Este modelo es muy similar al jerárquico, pero su diferencia principal es el manejo del concepto de los nodos; permite que un nodo pueda tener varios nodos padres. El enfoque en el manejo de los nodos representa una mejora significativa respecto al modelo jerárquico, en razón de que posibilita solucionar el problema de la redundancia de datos.
Con toda la complejidad que resulta de la implementación de una base de datos de red ha provocado que esta sea empleada mayormente por programadores y no por usuarios finales.
•Base de datos relacional
Fue creada en 1970 por Edgar Codd en la IBM, en San Jose California, cuando formuló sus postulados fundamentales. Como su nombre lo indica, el modelo basa su funcionamiento de establecimiento de relaciones, consideradas como una representacion lógica de conjuntos o tuplas. En otras palabras, las bases de datos relacionales representan relaciones entre tablas compuestas de registros o filas que representan a las tuplas y campos o columnas.
En el modelo relacional, la forma de almacenar la informacion pasa a un segundo término, lo que permite que sea más sencillo de entender y usar por los usuarios finales. El modo de almacenar y recuperar la información en este modelo se hace mediante “consultas”, empleando un lenguaje especializado denominado SQL (lenguaje estructurado de consulta), que permite a los usuarios una forma flexible y dinámica para administrar la información. Estas características hacen que las bases de datos relacionadas sean ampliamente utilizadas en la actualidad.
•Bases de datos multidimensionales
Son bases especializadas desarrolladas para trabajar en conjunto con aplicaciones específicas, como el caso de los cubos OLAP. Muy similares en la relación, se distinguen de éstas en el manejo de conceptos, ya que los campos y atributos asociados a una tabla pueden pertenecer a dos tipos, ya sea que sirvan para representar las dimensiones de una tabla o métricas, que serán estudiadas.
•Base de datos orientados a objetos
Con el desarrollo del paradigma de la programación orientada a objetos, las bases de datos debían ser ajustadas a este mismo paradigma; el resultado fue el modelo orientado a objetos. Así, este tipo de base de datos almacena y manipula objetos (definidos a partir del paradigma de objetos, incorporando los conceptos de herencia, encapsulamiento, polimorfismo, entre otros).
•Gestión de base de datos distribuida (SGBD)
Con el auge de las telecomunicaciones e Internet surge la base de datos que puede estar contenida en diversos servidores a través de una red, así como el software empleado para su administración.
Dentro del software de administración de base de datos (SGBD) hay dos tipos básicos:
•Distribuidos homogéneos
Hacen referencia a un mismo tipo de software de administración de base de datos empleado en diversos servidores.
•Distribuidos heterogéneos
Tienen cierto grado de autonomía sobre el servidor, en donde se encuentran instalados y posibilitan el acceso y gestión de varias bases de datos autónomas y creadas al momento de la instalación del mismo software. La arquitectura empleada con mayor frecuencia para su funcionamiento es la del cliente-servidor, que permite a los usuarios conectarse de forma remota para unir base de datos en diferentes zonas geográficas y acceder a diversos sitios, como universidades y comercios. Deben su existencia a la aparición de organismos descentralizados.
•Base de datos documental
Permite generar índices en documentos completos, lo que posibilita realizar búsquedas de información más completas. Un ejemplo de sistemas que emplea este tipo de base de datos es el Tesaurus.
•Base de datos deductiva
También denominada base lógica o de conocimientos, es ampliamente utilizada en el campo de la inteligencia artificial; basa su funcionamiento en reglas de inferencia que permiten al sistema deducir un hecho a partir de una serie de conocimientos previos almacenados a ella.